Understanding the Advantages of Dyna in Reinforcement Learning
In reinforcement learning (RL), agents typically learn by interacting with an environment and collecting samples over time. However, this can be extremely data-intensive and time-consuming, especially in real-world applications where data is expensive or slow to gather. This is where Dyna, a hybrid model-based algorithm introduced by Richard Sutton, offers a significant advantage — improved sample efficiency.
What Is Dyna?
Dyna integrates two key ideas in reinforcement learning:
- Model-free learning: Learning directly from interaction with the environment.
- Model-based planning: Building an internal model of the environment and simulating experience to improve policy.
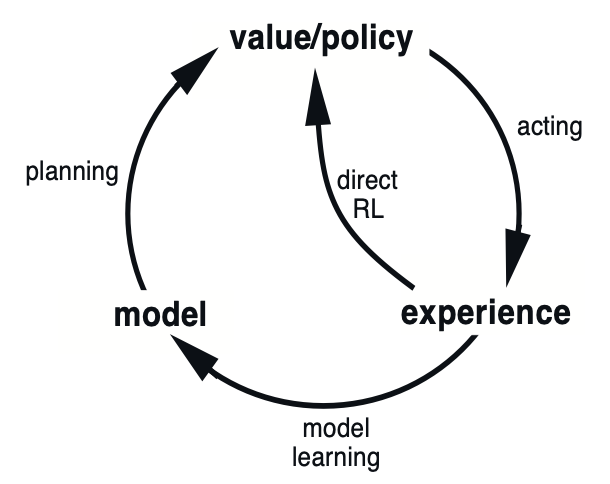
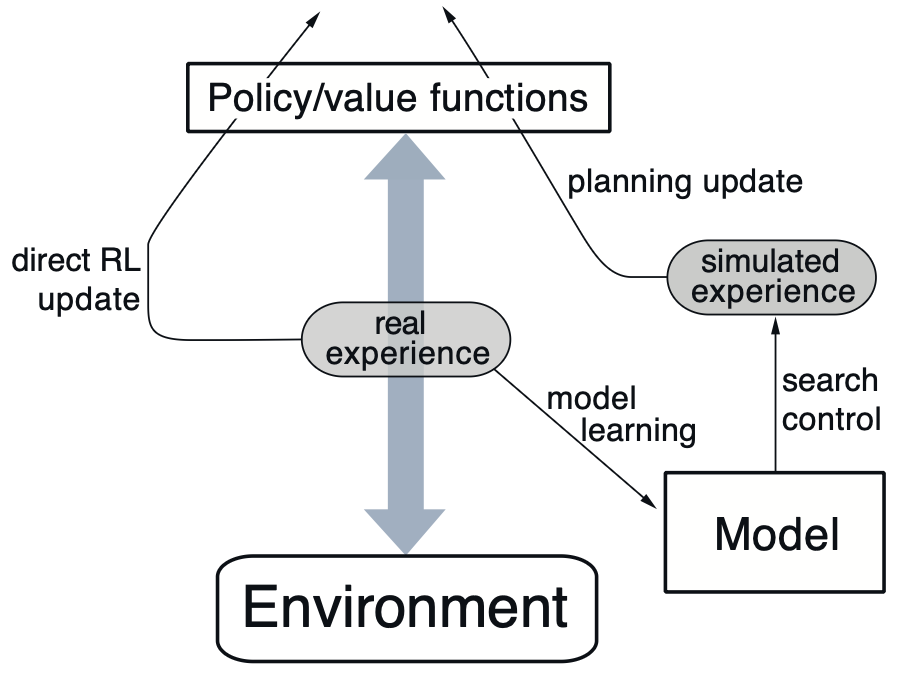
In Dyna, an agent learns a model of the environment (i.e., the transition and reward functions) while performing model-free learning. After each real-world interaction, the agent performs multiple planning updates by simulating experiences using the learned model.
Key Advantage: Improved Sample Efficiency
The primary benefit of Dyna is its dramatically increased sample efficiency. Here's how:
- Real experiences are reused more effectively. After each actual environment interaction, the agent generates multiple imaginary updates using its internal model. This means more learning per sample.
- This is particularly valuable when real interactions are expensive — such as in robotics, autonomous driving, or healthcare applications — where reducing the number of samples needed to learn a good policy can save both time and resources.
- Even a crude model can significantly accelerate learning compared to model-free methods alone.
Other Benefits
While sample efficiency is the core strength, Dyna also offers:
- Faster convergence: Leveraging both real and simulated experiences enables faster policy updates.
- Online adaptability: Dyna naturally fits into online learning settings, where the model is continually refined during interaction.
- Unified framework: It bridges the gap between model-free and model-based methods, combining their strengths while mitigating some of their weaknesses.
Considerations and Limitations
While Dyna is powerful, it's not without caveats:
- The learned model can introduce bias if it's inaccurate.
- Planning using the model may not be helpful in highly stochastic environments unless the model can capture that uncertainty.
- In complex domains, learning an accurate model itself may require substantial effort.
Conclusion
Dyna presents a compelling approach to reinforcement learning by combining direct experience with simulated planning. Its key strength — enhanced sample efficiency — makes it especially appealing for domains where data collection is costly or limited. As RL continues to move toward real-world applications, hybrid methods like Dyna are becoming increasingly relevant and valuable.