Modular RL Agent Architecture for Adaptive Environments
As environmental contexts in architectural design automation continuously evolve, it's crucial that our reinforcement learning(RL) agents remain flexible and easily updatable. To accommodate frequent changes—such as adding new entity types, modifying observation formats, or replacing sub-policies—I adopted a component-based model composition strategy.
Modular Component Design
The RL agent is decomposed into interchangeable components at multiple levels:
- State encoders (e.g., CNN, GNN, Transformer)
- Action heads (e.g., for different action types: entity selection, parameter prediction)
- Value networks or critics
- Training utilities and schedulers
These components are defined separately, and the overall agent architecture is constructed via a simple configuration file (e.g., YAML or JSON). Users can swap, extend, or modify components without rewriting core code—allowing rapid adaptation to new tasks or environmental updates.
Benefits of the Modular Approach
-
Scalability
- Easy to add new action heads or encoders as new entity types or design tasks emerge.
-
Maintainability
- Individual modules can be debugged, optimized, or unit-tested in isolation.
-
Reusability
- Shared components (e.g., a common encoder or RL backbone) can be reused across different designs or projects.
-
Configurability
- Non-developers or researchers can prototype new architectures by editing a config file—no need to dive into the codebase.
-
Robustness to Change
- When the environment's API or observation space changes, only the relevant module needs adjustment, not the whole agent.
Implementation Highlights from the unirl Repo
- Component Registry: a Python factory that maps config names to class constructors
- Declarative Config File: defines agent structure—encoders, heads, optimizers, etc.
- Dynamic Model Assembly: core
RlModelclass reads config, instantiates modules, and wires them together - Plug-and-Play Training Loop: the same trainer works seamlessly regardless of architecture variations
- Minimal Boilerplate: users only write new components and update the config—no need to modify the training framework
Overall architecture
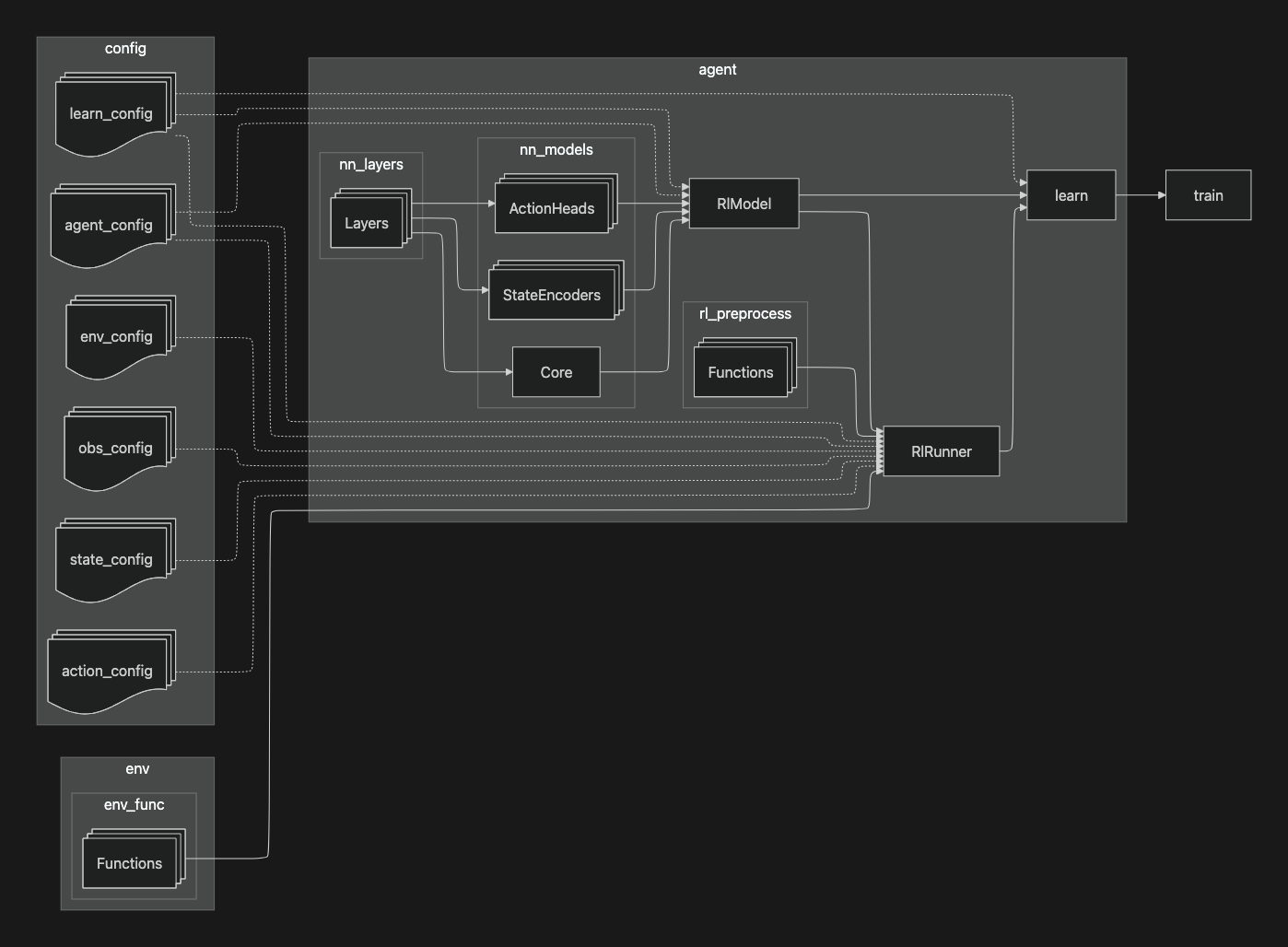
This diagram illustrates the overall architecture and dependency flow of the unirl framework.
-
configs: multiple YAML configuration files define the behavior of different components
- learn_config: training hyperparameters.
- agent_config: model structure and agent-specific parameters.
- env_config: environment setup.
- obs_config: observation structure.
- state_config: how states are built from observations.
- action_config: action space definition.
-
env_func: contains environment logic, such as step() and reset() functions.
-
agent:
- nn_layers: provides low-level neural network building blocks.
- nn_models: uses nn_layers to define reusable components
- ActionHeads for different action types.
- StateEncoders for different input modalities.
- Core as a shared backbone.
- RlModel assembles nn_models according to the configs, producing the complete neural network policy and value functions.
- rl_preprocess: defines functions to convert raw observations into encoded states suitable for the model.
- RlRunner: coordinates environment interaction, applying preprocessing and invoking the model to produce actions, collect rollouts, and create training batches.
-
learn: drives the training loop: it uses the RlRunner to gather experience batches and updates the assembled RlModel.
-
train: serves as an entry point, loading the configs and invoking learn.
Overall, the diagram shows how configuration, model components, preprocessing, environment, and learning logic are interconnected to create a modular and easily reconfigurable reinforcement learning system.
Information flow
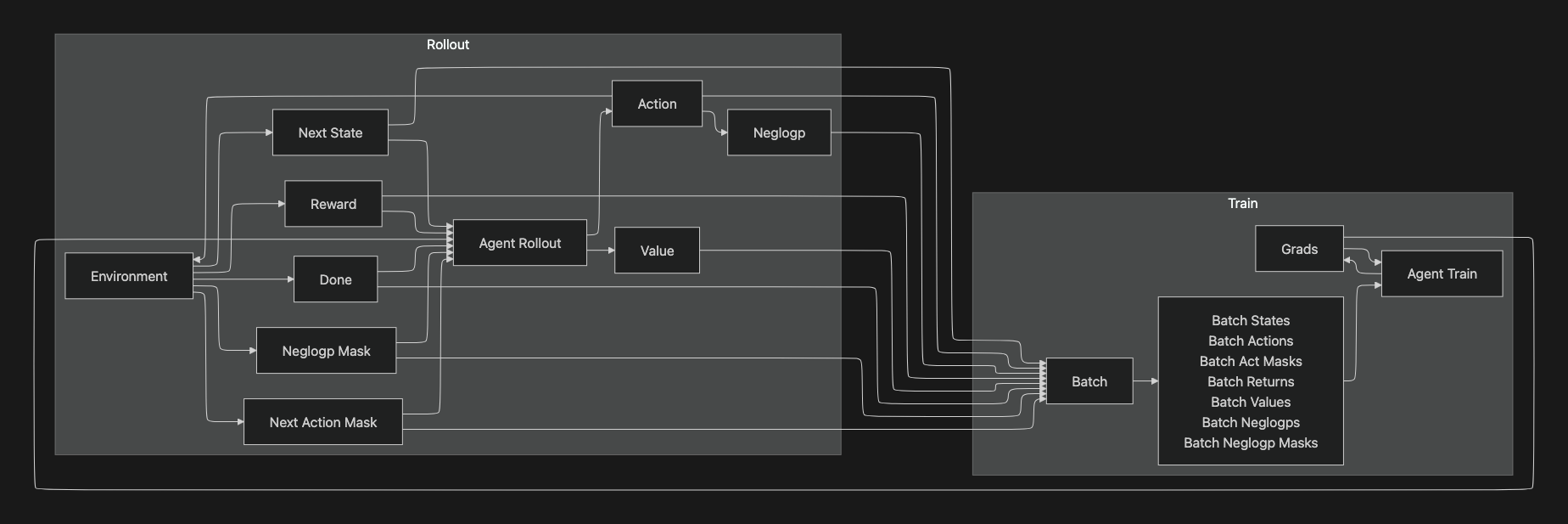
This diagram shows the interaction between the Rollout and Train phases in the unirl framework.
-
Rollout
- Environment: the simulation or environment which produces:
- Next State: the next state from observation after an action.
- Reward: the scalar feedback signal.
- Done: a boolean indicating episode termination.
- Neglogp Mask: action availability constraints used in loss calculation.
- Next Action Mask: constraints on the next action selection.
- Agent Rollout: uses the current policy to produce:
- Action: chosen according to the policy.
- Neglogp: negative log-probability of the selected action(for policy-gradient algorithms).
- Value: estimated state value.
- Environment: the simulation or environment which produces:
-
Batch
- All outputs from the rollout—states, actions, masks, returns, values, neglogps—are aggregated into a Batch for training.
-
Train
- Agent Train: consumes the batch and computes Grads(gradients). Grads are fed back to update the model’s parameters, completing the training loop. This updated model is then used for the next rollout cycle.
Overall, the diagram captures the information flow loop between environment interaction(rollout) and parameter optimization(train), showing exactly which variables are passed between components.
Distributed system
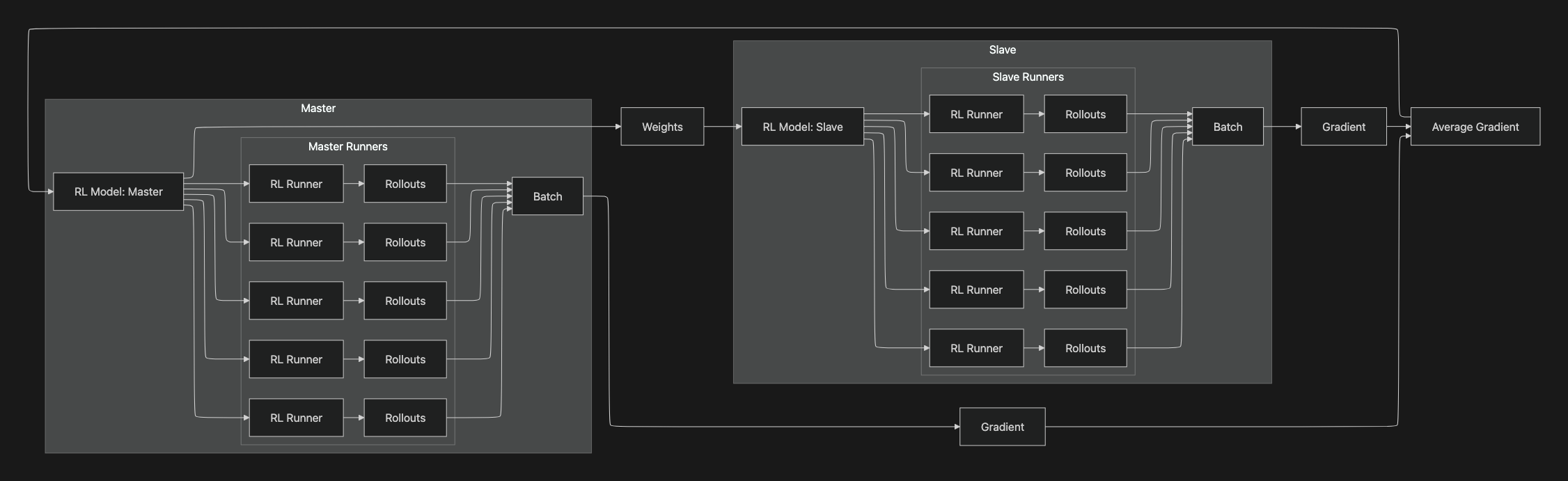
This diagram shows unirls distributed training loop with a Master–Slave setup.
-
Master side
- RL Model: Master
- Holds the authoritative weights.
- Master Runners → Rollouts → Batch
- Multiple runner processes interact with environments using the current master weights, produce rollouts, and aggregate them into a Batch(states, actions, masks, returns, values, neglogps, etc.).
- Weights → RL Model: Slave
- The master periodically broadcasts weights to the slave node so its runners collect on-policy (or near on-policy) data.
- RL Model: Master
-
Slave side
- RL Model: Slave
- A synchronized copy of the master used only for data collection.
- Slave Runners → Rollouts → Batch
- Parallel runners generate additional experience and build a Batch for training.
- Batch → Gradient
- The slave computes per-worker gradients from its batch and sends them back.
- RL Model: Slave
-
Aggregation & update
- Gradient → Average Gradient
- Gradients from master and slave batches are averaged(e.g., mean across workers/devices).
- Average Gradient → RL Model: Master
- The master applies the averaged gradient to update the parameters.
- Loop
- Updated weights are broadcast again to the slave, and the collection/training cycle repeats.
- Gradient → Average Gradient
It separates data collection(many runners on both master and slave) from parameter authority(single master), enabling scalable throughput while keeping a single source of truth for updates.
Summary
The unirl codebase exemplifies a composable RL agent framework that aligns perfectly with the evolving nature of architectural automation:
- Promotes rapid experimentation with new architectural designs or sub-policies
- Enables clean separation of concerns, improving readability and testability
- Supports future-proof extensibility, ideal for research environments that continuously iterate on components